Vector Addition Example#
First Example#
Programming for the AIE is highly parallel. While one can designate kernels to individual AI Engines, the data movement outside of it is usually considered via a data graph. While there are different languages and standards one can use for these graphs, our examples employ C++ for the kernels and the graphs using the AMD Vitis compiler. Here is an example of the filestructure that is seen:
.
├── graph.hpp # Used for the graph
├── host.cpp # Initializes, runs, and ends the graph.
├── kernels
│ └── vadd_stream.cc # kernel definitions
└── kernels.hpp # definition of kernel
Although the naming convention is not necessarily the most relevant, Vitis needs to know what is your main file. In the settings, vitis-comp.json, of the project, appoint host.cpp as the Top-level File.
We will take a look inside the files for how we define the graph and call the kernel.
Our Top-level File will initialize our graph and control the times it is ran. But the definition of the dataflow itself is stored in graph.hpp.
#include "graph.hpp"
simpleGraph vadd_graph;
int main(int argc, char** argv) {
vadd_graph.init();
// Run graph for 128 samples
vadd_graph.run(128);
vadd_graph.end();
return 0;
}
The dataflow graph is a class that extends the graph functionality. It can be made up of a multiple kernels, snippets of code that will run on the AIE tiles. While multiple kernels can run per tile, a kernel is not split between tiles.
Our graph itself must define the data flow before it is ready to call on the kernels. In our implementation we use input_plio to stream our data from our plio memory to connect to the inputs of our kernel. We also need to specify the dimensions of our types from our inputs as well as our outputs. We use a stream to tell Vitis that we want to load via the stream interface and run the graph for 128 samples. Later, we will look at an alternative implementation that uses buffers instead of streams.
graph.hpp:
#include <adf.h>
#include "kernels.hpp"
using namespace adf;
// Defines a simple AI Engine graph
class simpleGraph : public graph {
private:
kernel vadd; // Vector addition kernel
public:
input_plio p_in0;
input_plio p_in1;
output_plio p_out0;
simpleGraph() {
vadd = kernel::create(aie_vadd_stream);
source(vadd) = "kernels/vadd_stream.cc";
// PLIOs mapped to text files for simulation I/O
p_in0 = input_plio::create("data_in0", plio_32_bits, "data/input0.txt");
p_in1 = input_plio::create("data_in1", plio_32_bits, "data/input1.txt");
p_out0 = output_plio::create("data_out0", plio_32_bits, "data/output.txt");
// Connect PLIOs and kernel using streams
connect<stream>(p_in0.out[0], vadd.in[0]);
connect<stream>(p_in1.out[0], vadd.in[1]);
connect<stream>(vadd.out[0], p_out0.in[0]);
// Set kernel runtime ratio for scheduling
runtime<ratio>(vadd) = 1;
};
};
Standard usage of a header file for declaration. We use this file to list our kernels, which for this example is limited to a single one.
kernels.hpp:
#include <adf/stream/types.h>
void aie_vadd_stream(input_stream_int32 *data_in0, input_stream_int32 *data_in1, output_stream_int32 *data_out0);
The definition of the our aie_vadd_stream() kernel. It takes in a stream of int32, which is specified by the architecture, places it into a vector of size 4 of types int32, and then uses functions to read continually from the stream and calculate the addition of both streams, storing it into the output stream.
kernels.hpp:
#include <adf.h>
#include<aie_api/aie_adf.hpp>
void aie_vadd_stream(input_stream_int32 *data_in0, input_stream_int32 *data_in1, output_stream_int32 *data_out0) {
aie::vector<int32, 4> a = readincr_v<4>(data_in0);
aie::vector<int32, 4> b = readincr_v<4>(data_in1);
aie::vector<int32, 4> result = aie::add(a,b);
writeincr_v<4>(data_out0, result);
}
Vitis’s analyzation is very useful to looking at the synthesized dataflow. Our final array view shows how the plio blocks stream into the AIE itself and streams the results back into an output. Notice that it does not use any of the tile’s local memory.
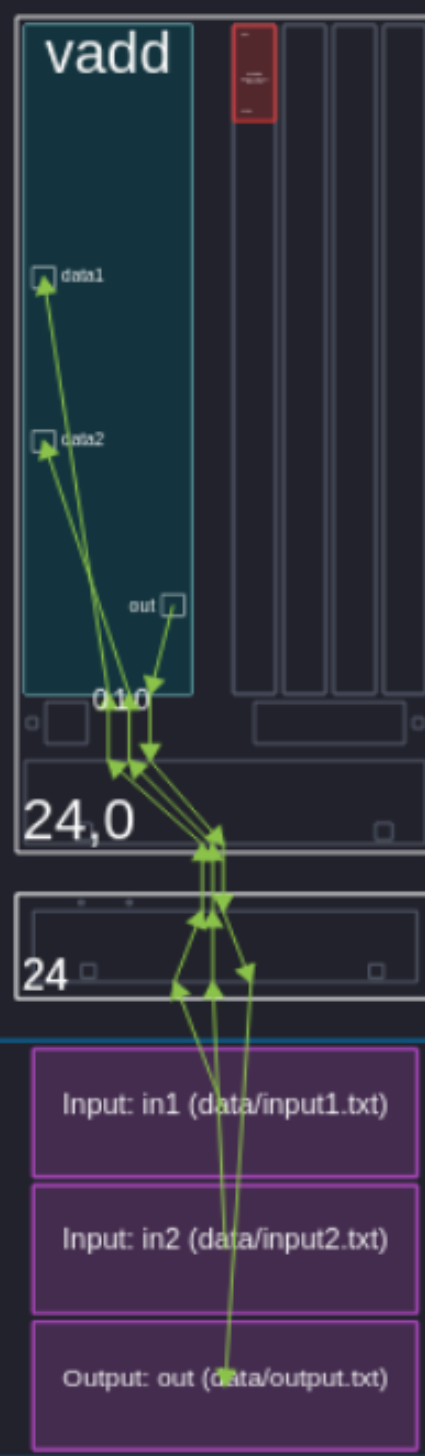
Second Example#
We also provide a second implementation of vector addition. In this example, we use aie::buffer instead of streams. This change to the dataflow type will store the entire input and outputs into the local tile memory so that it may be accessed all at once by the kernel. We also define iterating over inputs in the graph, not by running the graph 128 times, but using a vector iterator to access the local memory. Therefore instead of running the graph 128 times for each stream packet, we run it just once on the entire input vector.
As a result the aie::buffer has a higher pre-kernel overhead, because the kernel must wait for the entire buffer to be filled before it begins processing. However, it can be more efficient for larger data sets, as it reduces the overhead of repeatedly initializing the kernel with new data. [1]
From Vitis hardware simulation, the first element of the vector to be calculated and written to plio was at 4435200 ps which means the initial data buffering took over 50% of the kernel runtime on a vector of 1024 elements. Whereas, when we use the stream datatype, the pre-kernel streaming of data is negligible, because the first element is processed and written to plio almost immediately.
The stream datatype gave a quicker time to first element, which could be useful for real-time applications. However, the buffer datatype was marginally faster to process the entire vector (~200 ps), because it can exploit the parallelism of AIE processors more effectively.
host.cpp:
#include <adf.h>
#include "graph.h"
using namespace adf;
vecAddGraph v_graph;
int main(void) {
v_graph.init();
v_graph.run(1);
v_graph.end();
return 0;
}
graph.hpp:
#include <adf.h>
#include "kernels.h"
#define NUM_SAMPLES 1024
using namespace adf;
class vecAddGraph : public adf::graph {
private:
kernel vadd;
public:
input_plio in1;
input_plio in2;
output_plio out;
vecAddGraph(){
in1 = input_plio::create(plio_32_bits, "data/input1.txt");
in2 = input_plio::create(plio_32_bits, "data/input2.txt");
out = output_plio::create(plio_32_bits, "data/output.txt");
vadd = kernel::create(vector_add);
connect(in1.out[0], vadd.in[0]);
connect(in2.out[0], vadd.in[1]);
connect(vadd.out[0], out.in[0]);
dimensions(vadd.in[0]) = { NUM_SAMPLES };
dimensions(vadd.in[1]) = { NUM_SAMPLES };
dimensions(vadd.out[0]) = { NUM_SAMPLES };
source(vadd) = "kernels/kernels.cc";
runtime<ratio>(vadd) = 1.0;
}
};
kernel.h:
#include <adf.h>
using namespace adf;
void vector_add(input_buffer<int32> &data1, input_buffer<int32> &data2, output_buffer<int32> &out);
kernels/kernels.cc:
#include <aie_api/aie.hpp>
#include <adf.h>
using namespace adf;
void vector_add(input_buffer<int32> &data1, input_buffer<int32> &data2, output_buffer<int32> &out)
{
// The SIMD instructions can process 16 int32 per cycle (512b width vector registers)
auto inIter1 = aie::begin_vector<16>(data1);
auto inIter2 = aie::begin_vector<16>(data2);
auto outIter = aie::begin_vector<16>(out);
for (unsigned i = 0; i < data1.size() / 16; i++)
{
aie::vector<int32, 16> vec1 = *inIter1;
aie::vector<int32, 16> vec2 = *inIter2;
aie::vector<int32, 16> res = aie::add(vec1, vec2);
*outIter = res;
//Increment indices
inIter1++;
inIter2++;
outIter++;
}
}
The final array image shows us the usage of multiple tiles. Although the kernel runs in a single one, the usage of memory spreads throughout an adjacent tile.

Summary#
Through vector addition, the differences between streams and buffers are explored.
Metric |
Buffer |
Stream |
|---|---|---|
Latency |
Higher (wait for buffer fill) |
Lower (immediate processing) |
Throughput |
Higher (256-bit/cycle operations) |
Lower (32-bit/cycle operations) |
Best Use Case |
Large datasets, random access |
Real-time, low-latency apps |