Simple Multi-Tile Matrix Multiplication (16x16x16)#
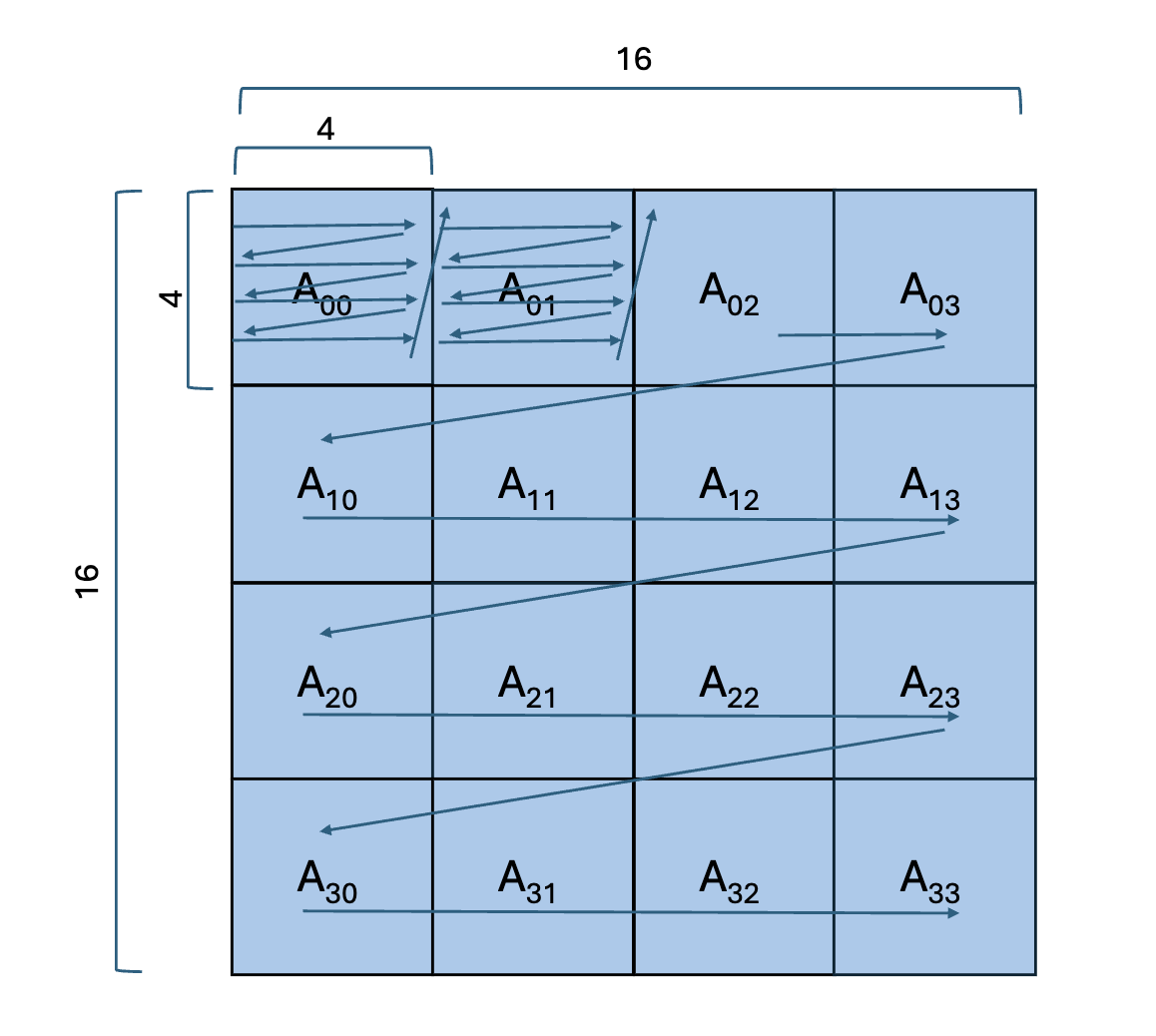
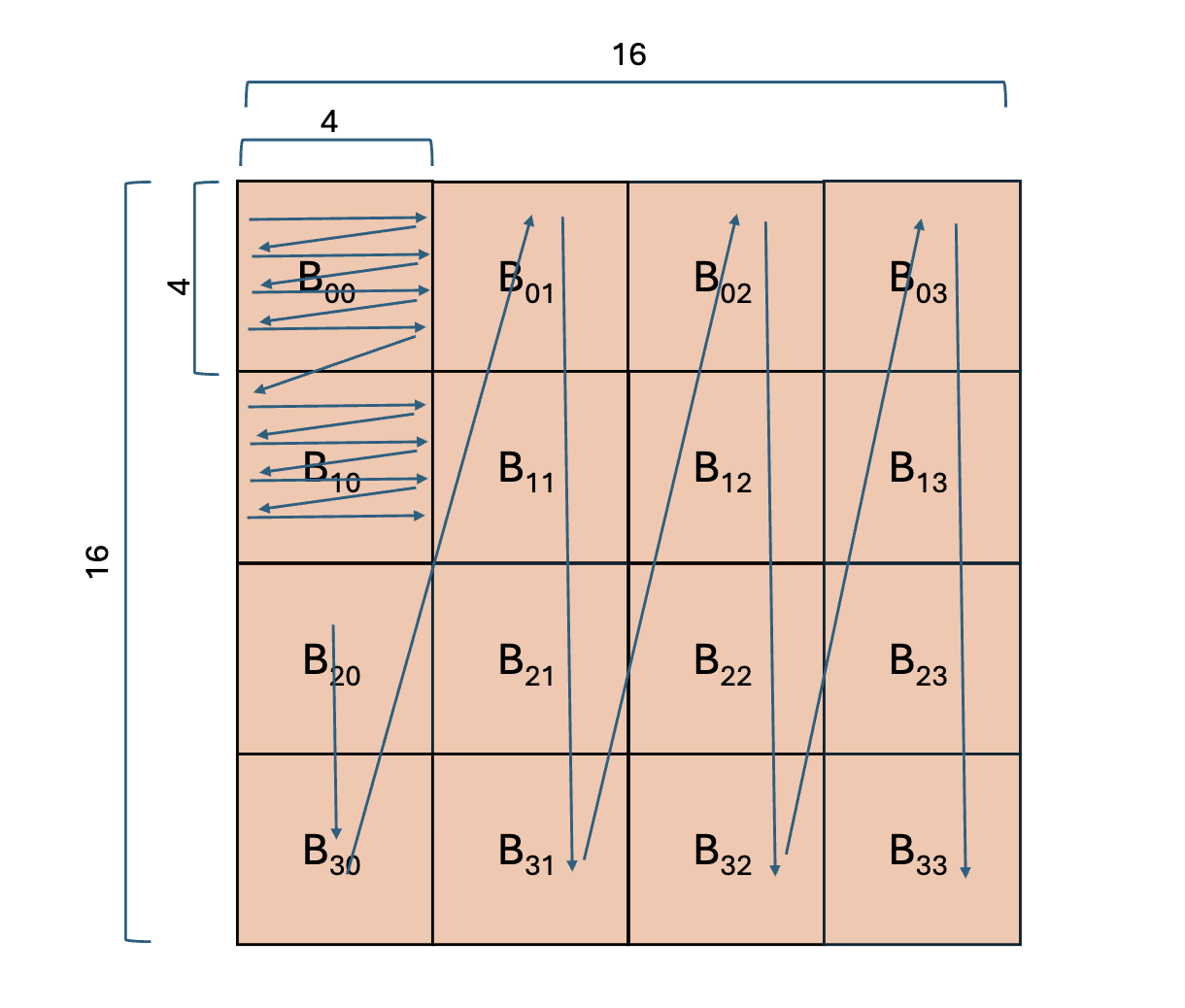
The mmul API class [1] offers 4x4x4 built-in matrix multiplication for int16. The following program calculates A*B=C where A, B, and C are matrices, and the computation is split across 16 tiles. Both 16x16 input matrices are split into 4x4 blocks. Within a block, row-major format is used. For matrix A, at the block-level, row-major format is used. For matrix B, a block-level column-major scheme is implemented.
Matrix A Traversal |
Matrix B Traversal |
|---|---|
|
|
Within a kernel, each corresponding block from A and B are multiplied and those partial results are summed together. The mmul class provides the mmul::mac() function with will perform acc = acc + A*B where acc is the (vectorized) values in the accumulator register corresponding to different sub-computations of the output matrix C.
Note that the AIE API docs provides a more general GEMM example kernel [2] for reference.
File structure:
.
├── graph.hpp # Declaration of the graph
├── graph.cpp # Initializes, runs, and ends the graph.
├── kernels
│ └── kernels.cpp # matmul kernel implementation
└── kernels.hpp # declarations of kernel
Kernel Code (kernels.cpp)#
Here is an example of a kernel that performs 4x16x4 matrix multiplication for int16. There is no mmul class to accommodate the larger matrix size. Instead the computation is broken up into 4x4x4 multiplications and partial results are added together using mmul::mac().
The sizes provided by the mmul class are limited by the width of the accumulator register, which is by default 48 bits for int16. The a_block and b_block parameters are used to determine the offset of the larger A and B matrices where the kernel will read from. If a_block = 0 and b_block = 0, the kernel will read from the top left corner of the A and B matrices, and ultimately calculate the top left 4x4 block (C00) of the output matrix C.
#include <aie_api/aie.hpp>
#include <adf.h>
using namespace adf;
// Define the sub-matrix multiplication sizes
using MMUL = aie::mmul<4, 4, 4, int16, int16>;
void matmul_4x16x4(
input_buffer<int16>& __restrict a,
input_buffer<int16>& __restrict b,
output_buffer<int16>& __restrict c,
int a_block, int b_block)
{
auto a_iter = aie::begin_vector<MMUL::size_A>(a) + a_block*4;
auto b_iter = aie::begin_vector<MMUL::size_B>(b) + b_block*4;
auto c_iter = aie::begin_vector<MMUL::size_C>(c);
MMUL m;
// First iteration: initialize accumulator
m.mul(*a_iter++, *b_iter++); // m.acc = A0 * B0
// Subsequent iterations: multiply-accumulate
for(int i = 1; i < 4; i++) {
m.mac(*a_iter++, *b_iter++); // m.acc += A_i * B_i
}
// Single store at end
*c_iter = m.to_vector<int16>();
}
The 4x16x4 kernel is duplicated across 16 tiles to calculate a 16x16x16 matrix multiplication in parallel.
Graph Code (graph.h)#
Here is the graph code. Note that this code broadcast the A and B matrices to all tiles. The inputs are thus duplicated 16 times(!) in local tile memory. A more memory-efficient approache is discussed in the next section, but this serves as a simple reference example.
#include <adf.h>
#include "kernels.h"
#include "include.h"
using namespace adf;
class MatMulGraph : public graph {
public:
input_plio a_in;
input_plio b_in;
output_plio c_out[4][4];
// Define input ports which determine the section of the matrix that a single kernel will compute.
input_port a_block_param[4][4];
input_port b_block_param[4][4];
kernel mmul[4][4];
MatMulGraph() {
a_in = input_plio::create("A_Matrix", plio_128_bits, "data/A_matrix.txt");
b_in = input_plio::create("B_Matrix", plio_128_bits, "data/B_matrix.txt");
// Create 4x4 kernel grid
for(int row=0; row<4; row++) {
for(int col=0; col<4; col++) {
mmul[row][col] = kernel::create(matmul_4x16x4);
// Connect A row block (16x16 = 256 elements)
connect(a_in.out[0], mmul[row][col].in[0]);
dimensions(mmul[row][col].in[0]) = {256};
// Connect B column block (16x16 = 256 elements)
connect(b_in.out[0], mmul[row][col].in[1]);
dimensions(mmul[row][col].in[1]) = {256};
// Connect parameter ports
connect(a_block_param[row][col], mmul[row][col].in[2]);
connect(b_block_param[row][col], mmul[row][col].in[3]);
// Create PLIO with 32-bit interface for 4x4 int16 blocks
c_out[row][col] = output_plio::create(
plio_128_bits,
"data/C_output_"+std::to_string(row)+"_"+std::to_string(col)+".txt"
);
connect(mmul[row][col].out[0], c_out[row][col].in[0]);
// Set buffer dimensions (16 int16 elements = 4x4 matrix)
dimensions(mmul[row][col].out[0]) = {16};
// Map to physical tiles
location<kernel>(mmul[row][col]) = tile(row, col);
source(mmul[row][col]) = "src/kernels/kernels.cpp";
runtime<ratio>(mmul[row][col]) = 1.0;
}
}
}
}
The graph code initializes the global PLIO streams for the input matrices A and B, and output matrix C. The input ports a_block_param and b_block_param are defined to determine the section of the matrix that a single kernel will compute. They are simular to threadIDs in GPU programming and play the same role. They are single scalar values which are translated to the a_block and b_block parameters in the kernel code. In the host code, we set this grid of parameters.
Host Code (host.cpp)#
The host code calls the graph and sets the hyper-parameters a_block_param and b_block_param. They allow a kernel to know which block of the larger matrix it should compute.
These parameters are streamed in as initial data packets prior to the other data. These are static parameters that don’t change during runtime. Alternative, cleaner ways to set these kernel parameters during compile-time are discussed in the next module.
#include <adf.h>
#include "kernels.h"
#include "graph.h"
#include "include.h"
using namespace adf;
MatMulGraph mmul_graph;
int main(void) {
mmul_graph.init();
for(int row=0; row<4; row++) {
for(int col=0; col<4; col++) {
mmul_graph.update(mmul_graph.a_block_param[row][col], row);
mmul_graph.update(mmul_graph.b_block_param[row][col], col);
}
}
mmul_graph.run(1);
mmul_graph.end();
return 0;
}
AIE Grid Array View#
AMD Vitis software simulation provides a grid view of the AIE array:

The 4x4 kernel grid is mapped to the bottom left corner of the AIE grid as specified in the graph code. Note the double buffering which is automatically applied from plio to local tile buffers. If double buffering will exceed the memory limit of the local tiles, you can disable it with single_buffer(port<T>&) [3].
References