MNIST Multi-Layer Perceptron#
NOTE: This example is a work in progress. (Not finished) Please open a PR if you would like to add your example.
Here we provide a simple MLP for the MNIST data set. The input dimension is 28x28 which is flatten to a vector of 784 grayscale values (0 - 255). Inference is done with int16 weights on the AI Engine with an add-tree matrix multiplication design. A batch dimension of 4 is used to stay within the bounds of the local tile memory (32 KB).
We use the following architecture. The activations are RELU and the classifier function is simple argmax.
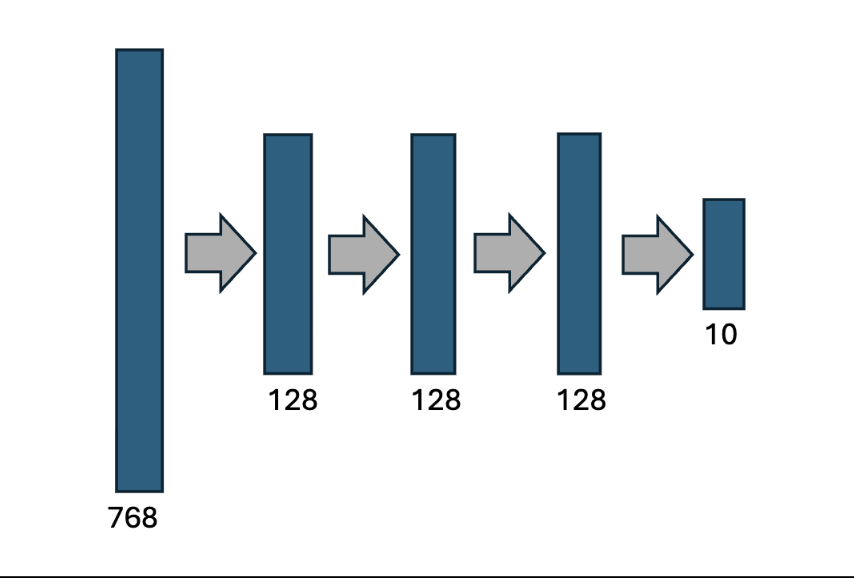
We first must build the hidden dense layers. Here is shown just the 128->128 layer.
Kernel Code (RELU Layer)#
void add_relu_4::run(
input_buffer<int16>& in0,
input_buffer<int16>& in1,
input_buffer<int16>& in2,
input_buffer<int16>& in3,
input_buffer<int16>& bias,
output_buffer<int16>& out
) {
// Vector iterators for VEC-element parallel processing
auto in0_iter = aie::begin_vector<VEC>(in0);
auto in1_iter = aie::begin_vector<VEC>(in1);
auto in2_iter = aie::begin_vector<VEC>(in2);
auto in3_iter = aie::begin_vector<VEC>(in3);
auto out_iter = aie::begin_vector<VEC>(out);
// Process all elements in vector chunks
for(int row = 0; row < N; ++row) {
auto bias_iter = aie::begin_vector<VEC>(bias);
for (int col = 0; col < M/VEC; ++col) {
aie::vector<int16, VEC> v0 = *in0_iter++;
aie::vector<int16, VEC> v1 = *in1_iter++;
aie::vector<int16, VEC> v2 = *in2_iter++;
aie::vector<int16, VEC> v3 = *in3_iter++;
aie::vector<int16, VEC> v_bias = *bias_iter++;
// Vector addition with saturation
aie::vector<int16, VEC> sum = aie::add(aie::add(v0, v1),
aie::add(v2, v3));
sum = aie::add(v_bias, sum);
aie::vector<int16, VEC> relu = aie::max(sum, aie::broadcast<int16, VEC>(0));
*out_iter++ = relu;
}
}
}
Graph Code (layer.h)#
class layer_128x128 : public adf::graph {
private:
const unsigned int K = 128;
const unsigned int M = 128;
const unsigned int T = 4;
public:
kernel mmul[4];
kernel add;
input_plio in_A;
input_plio in_B[4];
input_plio in_bias;
output_plio out_C;
layer_128x128(int layer_param) {
in_A = input_plio::create(plio_128_bits, "data/A_matrix.txt");
in_bias = input_plio::create(plio_128_bits, "data/bias_"+std::to_string(layer_param)+".txt");
out_C = output_plio::create(plio_128_bits, "data/C_output.txt");
add = kernel::create_object<add_relu_4>(M);
source(add) = "src/kernels/add_tree_relu.cpp";
runtime<ratio>(add) = 1.0;
dimensions(add.out[0]) = {N*M};
dimensions(add.in[4]) = {M};
connect(add.out[0], out_C.in[0]);
connect(in_bias.out[0], add.in[4]);
for (unsigned int i = 0; i < N; ++i) {
dimensions(add.in[i]) = {N*M};
in_B[i] = input_plio::create(plio_128_bits, "data/B_"+std::to_string(i)+ ".txt");
mmul[i] = kernel::create_object<mmul_skinny>(K, M, T, i);
runtime<ratio>(mmul[i]) = 1.0;
dimensions(mmul[i].in[0]) = {N*K};
dimensions(mmul[i].in[1]) = {M*(K/4)};
dimensions(mmul[i].out[0]) = {N*M};
connect(in_A.out[0], mmul[i].in[0]);
connect(in_B[i].out[0], mmul[i].in[1]);
connect(mmul[i].out[0], add.in[i]);
source(mmul[i]) = "src/kernels/kernels.cpp";
}
location<kernel>(add) = tile(0, 1);
location<kernel>(mmul[0]) = tile(0, 0);
location<kernel>(mmul[1]) = tile(1, 1);
location<kernel>(mmul[2]) = tile(0, 2);
location<kernel>(mmul[3]) = tile(1, 0);
}
};
Then we link the layers together to create the entire MLP. Note how our MLP graph calls other graphs.
Graph Code (MLP.h)#
#include <adf.h>
#include "kernels.h"
#include <aie_api/aie_adf.hpp>
#include "include.h"
#include "layers.h"
using namespace adf;
class MLP: public adf::graph {
public:
input_plio in_A;
output_plio out_C;
layer_768x128 layer1;
layer_128x128 layer2;
layer_128x128 layer3;
layer_128x10 classifier;
MLP()
: layer1(0), layer2(1), layer3(2)
{
in_A = input_plio::create(plio_128_bits, "data/images.txt");
connect(in_A.out[0], layer1.in_A);
connect(layer1.out_C, layer2.in_A);
connect(layer2.out_C, layer3.in_A);
connect(layer3.out_C, out_C.in[0]);
}
}
Finally we run our host code on an input instance.
Host Code (MLP.cpp)#
#include <adf.h>
#include "layers.h"
#include "MLP.h"
#include "include.h"
using namespace adf;
MLP mlp_graph;
int main(void) {
mlp_graph.init();
// Update block parameters
for (int i = 0; i < T; ++i) {
mlp_graph.update(mlp_graph.layer1.a_block_param[i], i*(K/T/32));
}
mlp_graph.run(1);
mlp_graph.end();
return 0;
}
Note that we include this example for our reference but it is not fully working/complete at this time (6/9/25)